I finally started working on ud-chains for Mesa's GLSL compiler. I'm
continually amazed that it works as well as it does without them. There are
so many ugly hacks and so much ad hoc data-flow analysis that I just couldn't
put it off any longer. If you want to cry, take a look at how reaching
definitions are determined in
loop_analysis.cpp.
It's pretty horrible.
My primary goal is to get enough infrastructure in place to fix that code. In addition to the ugliness, it fails on cases like:
void main()
{
int n = 3;
int i = 0;
if (b)
some_function();
while (i < n) {
some_other_function();
}
}
The loop analyzer will have no idea what the values of i or n are. There
are similar issues with identifying values that are constant across all
iterations of the loop. In this case, flow control inside the loop confuses
the analyzer.
The first step to this project is to get real basic block tracking. We have a
mechanism to iterate over instructions as basic blocks (see
ir_basic_block.cpp,
but nothing is stored about the blocks. This means we don't know which
blocks can transfer control to which other blocks.
I now have some code that creates a the basic block structure of a function. The next step will be to process the instructions in the basic blocks to track the (value) definitions within the block.
In the mean time, I modified the stand-alone compiler to optionally dump a graph of the basic blocks in dot. The results, even for small shaders, are shockingly cool.
Here's the code for the piglit test
glsl-fs-vec4-indexing-temp-dst-in-nested-loop-combined.shader_test:
uniform float one;
uniform int count1, count2;
uniform vec4 red;
void main()
{
vec4 array[11];
array[0] = vec4(0.1, 0, 0, 0) * one;
array[1] = vec4(0, 0.1, 0, 0) * one;
array[2] = vec4(0, 0, 0.1, 0) * one;
array[3] = vec4(0, 0.1, 0, 0) * one;
array[4] = vec4(0, 0 , 0.1, 0) * one;
array[5] = vec4(0, 0, 0.1, 0) * one;
array[6] = vec4(0.1, 0, 0, 0) * one;
array[7] = vec4(0, 0.1, 0, 0) * one;
array[8] = vec4(0, 0.1, 0.1, 0) * one;
array[9] = vec4(0.1, 0.1, 0, 0) * one;
array[10] = vec4(0.1, 0, 0.1, 0) * one;
for (int i = 0; i < count1; i++)
for (int j = 0; j < count2; j++)
array[i*3+j] += red*float(j+1);
gl_FragColor = array[0] + array[1] + array[2] + array[3] + array[4] +
array[5] + array[6] + array[7] + array[8] + array[9] + array[10];
}
And here is the resulting basic block graph:
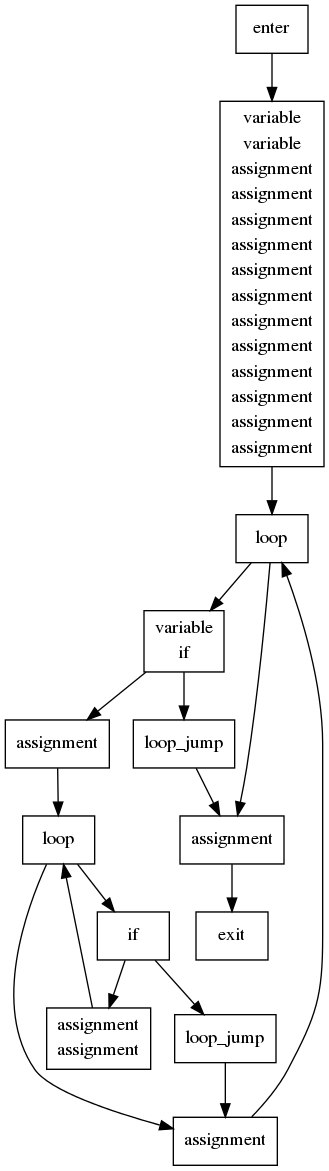
ud-chainsbranch of my personal GIT repo:git://anongit.freedesktop.org/~idr/mesa.gitI think compilers only support both if they predate ssa and have old optimization steps that use the ud chains. ssa is not an optimization itself but rather a special form of the intermediate language where each variable is only assigned once. In such a form ud chains are trivial, def is at an assignment and use is any op that references that variable name.
My compiler theory is a bit rusty, but I'm fairly sure about this.
I guess what I'm saying is, please don't add ud-chains and optimization passed based on it before implementing SSA, as then you'll have to rewrite those optimization passes when you switch to ssa form (and the implementation of the optimization passes are generally simpler when using ssa form).
Here is a book about SSA i found on google: http://ssabook.gforge.inria.fr/latest/book.pdf At least read some of it before deciding on using ud-chains.